
SQL语法基础篇
SQL是如何执行的?
Oracle 中的 SQL 是如何执行的
语法检查:检查 SQL 拼写是否正确,如果不正确,Oracle 会报语法错误。
语义检查:检查 SQL 中的访问对象是否存在。比如我们在写 SELECT 语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证 SQL 语句没有错误。
权限检查:看用户是否具备访问该数据的权限。
共享池检查:共享池(Shared Pool)是一块内存池,最主要的作用是缓存 SQL 语句和该语句的执行计划。Oracle 通过检查共享池是否存在 SQL 语句的执行计划,来判断进行软解析,还是硬解析。那软解析和硬解析又该怎么理解呢?
在共享池中,Oracle 首先对 SQL 语句进行 Hash 运算,然后根据 Hash 值在库缓存(Library Cache)中查找,如果存在 SQL 语句的执行计划,就直接拿来执行,直接进入“执行器”的环节,这就是软解析。
如果没有找到 SQL 语句和执行计划,Oracle 就需要创建解析树进行解析,生成执行计划,进入“优化器”这个步骤,这就是硬解析。
优化器:优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
执行器:当有了解析树和执行计划之后,就知道了 SQL 该怎么被执行,这样就可以在执行器中执行语句了。
MySQL 中的 SQL 是如何执行的
查询缓存:Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在 MySQL8.0 之后就抛弃了这个功能。
解析器:在解析器中对 SQL 语句进行语法分析、语义分析。
优化器:在优化器中会确定 SQL 语句的执行路径,比如是根据全表检索,还是根据索引来检索等。
执行器:在执行之前需要判断该用户是否具备权限,如果具备权限就执行 SQL 查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
DDL语句
在 DDL 中,我们常用的功能是增删改,分别对应的命令是 CREATE、DROP 和 ALTER。需要注意的是,在执行 DDL 的时候,不需要 COMMIT,就可以完成执行任务。
对数据库进行定义
CREATE DATABASE nba; // 创建一个名为 nba 的数据库
DROP DATABASE nba; // 删除一个名为 nba 的数据库对数据表进行定义
-- 创建表
CREATE TABLE table_name
-- 修改表结构
-- 添加字段
ALTER TABLE player ADD (age int(11));
-- 修改字段名
ALTER TABLE player RENAME COLUMN age to player_age
-- 删除字段
ALTER TABLE player DROP COLUMN player_age;SELECT语句
去除重复行
SELECT DISTINCT attack_range FROM herosDISTINCT 需要放到所有列名的前面,如果写成
SELECT name, DISTINCT attack_range FROM heros会报错。DISTINCT 其实是对后面所有列名的组合进行去重,你能看到最后的结果是 69 条,因为这 69 个英雄名称不同,都有攻击范围(attack_range)这个属性值。如果你想要看都有哪些不同的攻击范围(attack_range),只需要写
DISTINCT attack_range即可,后面不需要再加其他的列名了。
如何排序检索数据
排序的列名:ORDER BY 后面可以有一个或多个列名,如果是多个列名进行排序,会按照后面第一个列先进行排序,当第一列的值相同的时候,再按照第二列进行排序,以此类推。
排序的顺序:ORDER BY 后面可以注明排序规则,ASC 代表递增排序,DESC 代表递减排序。如果没有注明排序规则,默认情况下是按照 ASC 递增排序。我们很容易理解 ORDER BY 对数值类型字段的排序规则,但如果排序字段类型为文本数据,就需要参考数据库的设置方式了,这样才能判断 A 是在 B 之前,还是在 B 之后。比如使用 MySQL 在创建字段的时候设置为 BINARY 属性,就代表区分大小写。
非选择列排序:ORDER BY 可以使用非选择列进行排序,所以即使在 SELECT 后面没有这个列名,你同样可以放到 ORDER BY 后面进行排序。
ORDER BY 的位置:ORDER BY 通常位于 SELECT 语句的最后一条子句,否则会报错。
SELECT name, hp_max FROM heros ORDER BY mp_max, hp_max DESC 约束返回结果的数量
另外在查询过程中,我们可以约束返回结果的数量,使用 LIMIT 关键字。比如我们想返回英雄名称及最大生命值,按照最大生命值从高到低排序,返回 5 条记录即可。
SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5SELECT 的执行顺序
关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...ELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同)
FROM > WHERE > GROUP BY > HAVING > SELECT 的字段 > DISTINCT > ORDER BY > LIMIT比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7首先,你可以注意到,SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表 vt1,就可以在此基础上再进行 WHERE 阶段。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表 vt2。
然后进入第三步和第四步,也就是 GROUP 和 HAVING 阶段。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT 阶段。
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表 vt5-1 和 vt5-2。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段,得到虚拟表 vt6。
最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段,得到最终的结果,对应的是虚拟表 vt7。
当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
数据过滤
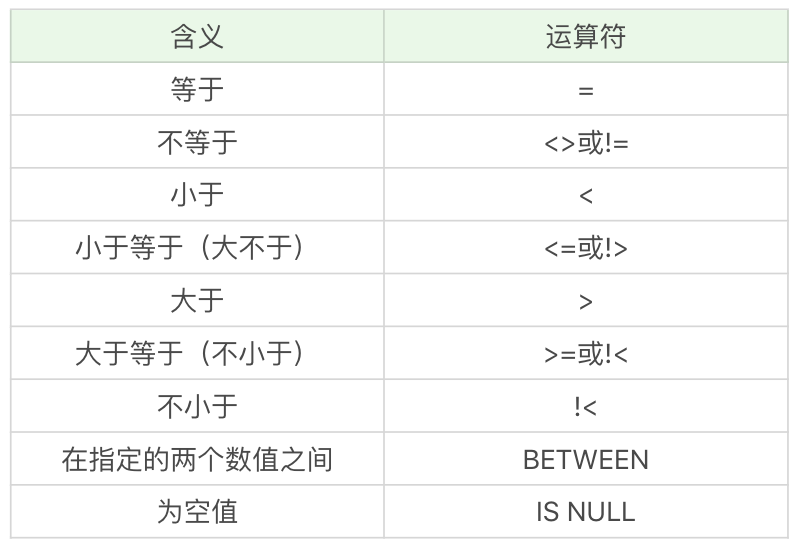
比较运算符
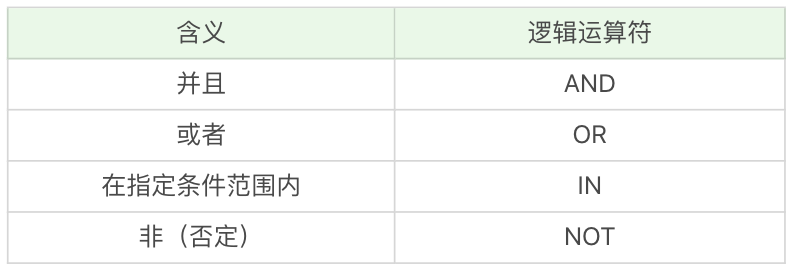
逻辑运算符
使用通配符进行过滤
通配符就是我们用来匹配值的一部分的特殊字符。这里我们需要使用到 LIKE 操作符。
需要说明的是不同 DBMS 对通配符的定义不同,在 Access 中使用的是(*)而不是(%)。另外关于字符串的搜索可能是需要区分大小写的,比如'liu%'就不能匹配上'LIU BEI'。具体是否区分大小写还需要考虑不同的 DBMS 以及它们的配置。
如果我们想要匹配单个字符,就需要使用下划线 (_) 通配符。(%)和(_)的区别在于,(%)代表一个或多个字符,而(_)只代表一个字符。比如我们想要查找英雄名除了第一个字以外,包含“太”字的英雄有哪些。
SELECT name FROM heros WHERE name LIKE '_% 太 %'在实际操作过程中,建议尽量少用通配符,因为它需要消耗数据库更长的时间来进行匹配。即使你对 LIKE 检索的字段进行了索引,索引的价值也可能会失效。如果要让索引生效,那么 LIKE 后面就不能以(%)开头,比如使用LIKE '%太%'或LIKE '%太'的时候就会对全表进行扫描。如果使用LIKE '太%',同时检索的字段进行了索引的时候,则不会进行全表扫描。
SQL函数
常见的SQL函数
算术函数
字符串函数
日期函数
转换函数
算术函数
算术函数,顾名思义就是对数值类型的字段进行算术运算。常用的算术函数及含义如下表所示:
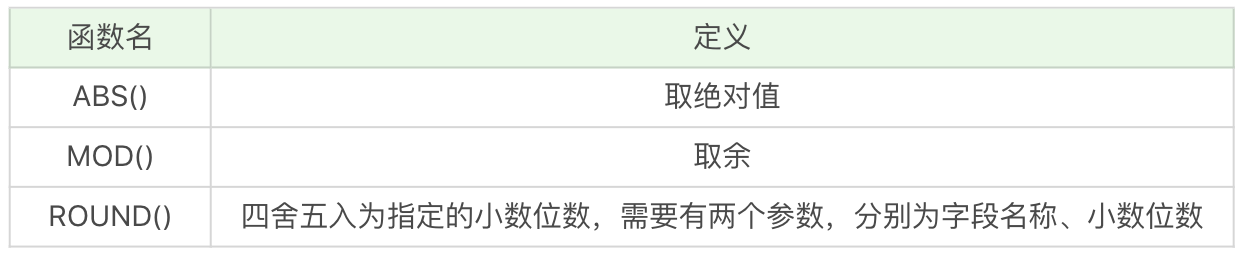
SELECT ABS(-2),运行结果为 2。
SELECT MOD(101,3),运行结果 2。
SELECT ROUND(37.25,1),运行结果 37.3。
字符串函数
常用的字符串函数操作包括了字符串拼接,大小写转换,求长度以及字符串替换和截取等。具体的函数名称及含义如下表所示:
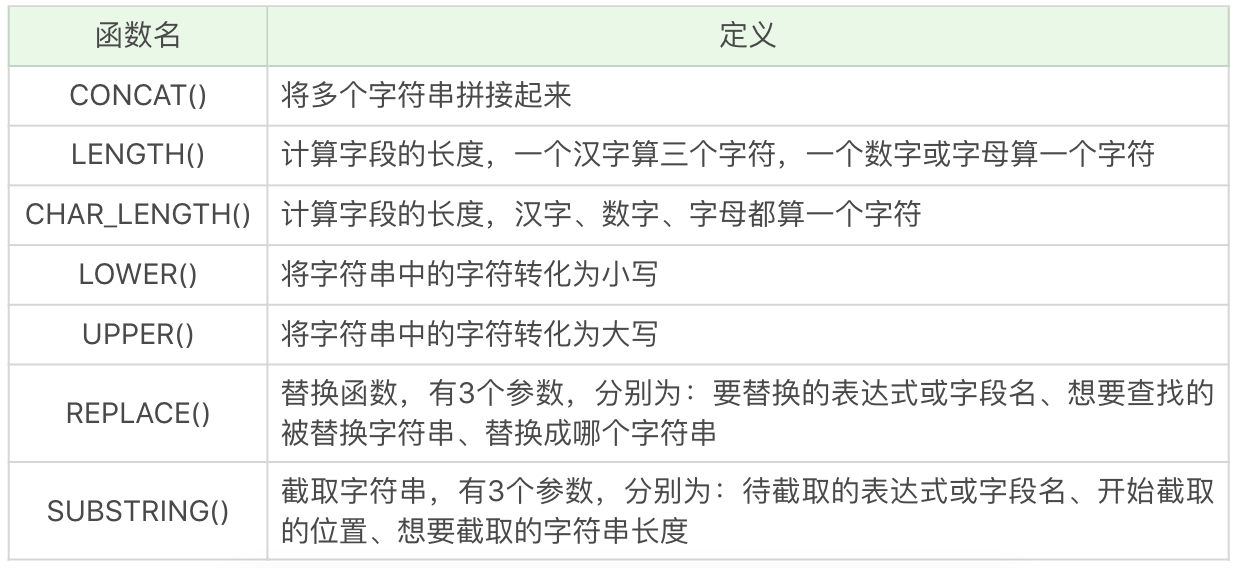
简单的例子:
SELECT CONCAT('abc', 123),运行结果为 abc123。
SELECT LENGTH('你好'),运行结果为 6。
SELECT CHAR_LENGTH('你好'),运行结果为 2。
SELECT LOWER('ABC'),运行结果为 abc。
SELECT UPPER('abc'),运行结果 ABC。
SELECT REPLACE('fabcd', 'abc', 123),运行结果为 f123d。
SELECT SUBSTRING('fabcd', 1,3),运行结果为 fab。
日期函数
日期函数是对数据表中的日期进行处理,常用的函数包括

简单的例子:
SELECT CURRENT_DATE(),运行结果为 2019-04-03。
SELECT CURRENT_TIME(),运行结果为 21:26:34。
SELECT CURRENT_TIMESTAMP(),运行结果为 2019-04-03 21:26:34。
SELECT EXTRACT(YEAR FROM '2019-04-03'),运行结果为 2019。
SELECT DATE('2019-04-01 12:00:05'),运行结果为 2019-04-01。
这里需要注意的是,DATE 日期格式必须是 yyyy-mm-dd 的形式。如果要进行日期比较,就要使用 DATE 函数,不要直接使用日期与字符串进行比较,我会在后面的例子中讲具体的原因。